- startups
- engineering-management
- monorepo
Monorepo vs Polyrepo: Team Structure Over Technology
You're starting a new project. Backend in Python. Frontend in TypeScript. Maybe some background jobs. The question comes up immediately: one repo or many?
13 min read
On this page
Someone on the team says “Google uses a monorepo.” Another person counters with “microservices need independence.” You Google it and find fifty blog posts with contradictory advice. None of them actually help you make the decision.
Here’s why: most frameworks optimize for the wrong thing. They focus on technology when the real question is about people and workflow.
Let’s explore together a potential decision framework that may actually work for you, using a real scenario that will reveal what actually matters.
The Setup: You’re Building FitnessFiction
You’re the founding engineer at FitnessFiction, an AI-powered fitness coaching platform. You report to the founder who handles product and business. You’re responsible for everything technical.
(Note: FitnessFiction is a hypothetical example created for this article to illustrate decision-making principles. Any resemblance to existing products is coincidental.)
Here’s what you’re building:
-
Mobile app (React Native): Users log meals and workouts
-
Backend API (Node.js): Auth, CRUD operations, data storage in PostgreSQL
-
AI/ML Pipeline (Python): Analyzes workout videos using computer vision, provides form correction feedback
-
Coach Dashboard (Next.js): Multi-tenant platform where fitness coaches manage their organizations, view their clients’ progress, and customize coaching workflows
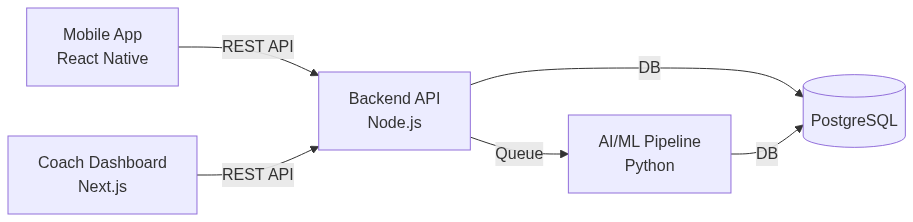
Your current structure:
fitnessfiction/ (Monorepo)
├── api/ (Node.js API)
├── mobile/ (React Native)
├── ml-pipeline/ (Python - video analysis)
├── coach-dashboard/ (Next.js)
└── .github/workflows/
└── deploy.ymlEverything lives in one repository. You work on features end to end, touching mobile, backend, ML pipeline, and coach dashboard in a single pull request.
The founder asks you: We want to scale this, how should we split this up as we grow?
The Trap Most Engineers Fall Into
The standard advice sounds reasonable at first:
-
“Use monorepo for code sharing”
-
“Use polyrepo for independence”
-
“Monorepo for small teams, polyrepo at scale”
But none of these actually help you decide. They describe outcomes, not decision criteria.
Code sharing is a benefit of monorepo, not a reason to choose it. This is like saying “buy a house if you want a backyard” when the actual question is whether buying a house makes sense for your situation.
The trap is optimizing for theoretical benefits instead of actual workflow.
Understanding how changes flow through your system matters far more than what the architecture diagram looks like or which build tools you’re using.
What Actually Matters: The Coupling Question
Here’s the first real question to ask:
Do your changes frequently span multiple services?
Not whether services could theoretically be independent. Not whether they use different languages. Whether your actual product changes touch multiple codebases.
Let’s trace through FitnessFiction to see what this means:
Scenario 1: Adding nutrition tracking
Which files do you need to change?
-
Backend: Add nutrition endpoints, database migration for meals table
-
Mobile: Add meal logging UI, nutrition display screens
-
Coach Dashboard: Add nutrition analytics view for coaches to monitor client diets
Three services touched in one feature. That’s tight coupling.
Scenario 2: Optimizing database queries
Which files do you need to change?
-
Backend: Update query logic, add indexes
-
Mobile: No changes (just receives faster responses)
-
Coach Dashboard: No changes (just loads faster)
One service touched. That’s loose coupling.
The insight here is critical. Coupling isn’t determined by your architecture diagram. It’s revealed by git history.
You look at your last twenty or so pull requests and find that seventy percent touch multiple services. That’s the signal that matters.
A quick caveat on measuring coupling:
Not all multi-service changes mean real coupling. Sometimes they happen because:
-
Immature API contracts
-
Lack of feature flags
-
Weak versioning discipline
That’s change coupling, fixable with better engineering practices.
Domain coupling is different. It means services share core business logic and models. That’s the coupling that matters for this decision.
For FitnessFiction, your features span mobile, backend, and coach dashboard because they share domain models: Users, Workouts, Progress. That’s real domain coupling, not just sloppy API design.
The Missing Factor: Team Structure
The number of teams owning coupled services matters more than the number of services.
Same codebase. Same services. Different team structures = completely different optimal decisions.
Your current reality:
You’re building features end to end.
Add nutrition tracking? You write:
-
Backend endpoint
-
Mobile UI
-
Coach dashboard interface
Everything exists in your mental model. No coordination needed. Nobody to coordinate with.
Decision for this case: Monorepo.
One pull request for complete features. Type safety across the stack. Zero coordination overhead.
But here’s the startup reality:
You don’t know if FitnessFiction will succeed or fail. You can’t predict whether you’ll hire specialists or stay generalist. You can’t foresee deployment constraints or organizational changes.
This uncertainty is why coupling matters most. It’s measurable today. Based on how your product actually works. Not hopes about team structure six months from now.
Putting these factors together
Here’s the decision tree that works for most startup teams:
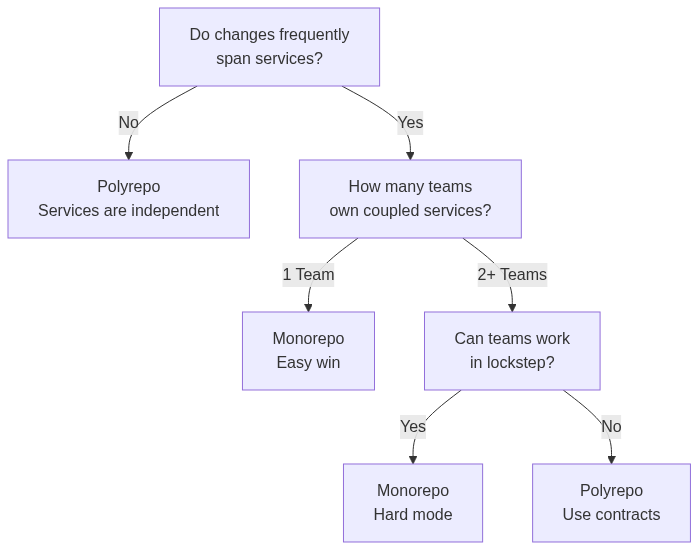
It works because it optimizes for the startup’s core strength: moving fast and adapting when things break
Structure repositories around coupling first. Ship features quickly now. Reorganize later when team structure or deployment realities force your hand.
This beats prematurely splitting repositories for hypothetical future scale. Then spending months fighting coordination overhead for a future that might never arrive.
Now let’s see what happens when reality introduces those unpredictable changes. Each variation shows when and why the decision shifts.
Applied to FitnessFiction right now:
-
Coupling: High (most features touch mobile and backend)
-
Teams: One (just you doing full-stack work)
-
Decision: Monorepo
Watch what happens when constraints change.
Variation 1: The Hiring Change
Six months later, you hire your first two engineers:
-
React Native specialist → owns mobile
-
Backend-heavy full-stack dev → owns API, coach dashboard, infra, optimizations
You shift focus to coach dashboard and business rules. The backend dev handles infrastructure. You collaborate in the same repository.
Same technical architecture. Same services. Different team structure.
The coordination problem appears:
The mobile dev builds nutrition tracking UI. But they need the API first. You build coach analytics for nutrition, sometimes pairing with the backend dev on API changes. The backend dev handles database schema and ML integration.
The key insight: mobile needs separation (different developer, different deployment). But API and coach dashboard stay together (you and backend dev collaborate in real-time).
You decide to restructure:
fitnessfiction-backend/ (You + Backend dev collaborate here)
├── api/ (Backend dev focuses here)
├── ml-pipeline/ (Backend dev owns this)
└── coach-dashboard/ (You focus here, can touch API when needed)
fitnessfiction-mobile/ (Mobile dev owns this)
└── app/ (React Native)Why this works:
Backend, ML pipeline, and coach dashboard stay together. They share:
-
Deployment pipelines
-
Domain models
-
Real-time coordination (you and backend dev work together)
Mobile separates. Different engineer, different priorities, different deployment schedule.
You set up OpenAPI to auto-generate TypeScript types for mobile. When the API changes, mobile gets updated types automatically. The mobile dev moves independently, coordinating only through the API contract.
The technical coupling didn’t change. The team structure and collaboration patterns changed. That shifted the decision.
Variation 2: The Deployment Reality
Your mobile app is in the App Store. Backend deploys twice daily. Mobile releases every two weeks (App Store review).
The problem:
Backend dev adds a field to the nutrition API. You update coach dashboard. Mobile dev updates mobile app. You and backend dev deploy in five minutes. Mobile dev submits to App Store. Waits a week.
What happens to users during that week? Old mobile code hits new backend API.
Your options:
-
Maintain backward compatibility → technical debt accumulates
-
Version the API → adds overhead
-
Hold back backend deploys → velocity dies
Deployment Speed ≠ Development Velocity:
CodePush can bypass App Store review. Sounds perfect, right?
Not quite. Deployment speed doesn’t equal development velocity. The mobile dev still needs time to build and test. If you and backend dev ship twice daily while mobile can only integrate changes every few days, the mismatch remains.
The structure that handles this:
fitnessfiction-backend/ (Deploys 2x/day - You + Backend dev)
├── api/ (Node.js - versioned endpoints)
├── ml-pipeline/ (Python - processes videos async)
└── coach-dashboard/ (Next.js - web deploys instantly)
fitnessfiction-mobile/ (Deploys every 2 weeks - Mobile dev)
└── app/ (React Native)This isn’t about team structure anymore. It’s about deployment physics.
Web properties (API, ML, coach dashboard) deploy instantly. You and backend dev coordinate in the same repo, deploy together.
Mobile lives in App Store reality. Apple controls the schedule.
Mobile in its own repo acknowledges this. Backend versions API endpoints (/v1/nutrition, /v2/nutrition). Deprecates old versions on a timeline. Mobile upgrades when it fits their schedule, not when backend deploys.
This is why web + mobile companies often use polyrepo even when small. App Store isn’t a team problem or coupling problem. It’s a deployment physics problem.
Variation 3: The ML Pipeline Addition
Your product is growing. The AI form correction feature needs serious improvement. Better computer vision models.
The problem: Neither you nor the backend dev have deep ML expertise.
The backend dev maintains the ML pipeline as infrastructure. But can’t push the models forward.
The solution: Hire a part-time computer vision specialist. They take over the ML pipeline.
The access control question:
Currently, the ML pipeline lives in the backend repository. Give the contractor access to the entire repo?
That means they see:
-
Proprietary scoring algorithms
-
Customer data schemas
-
Business intelligence queries
-
Business-secret type software
Probably not.
The naive fix: Git submodules or sparse checkouts.
But now you’re fighting the tools.
The simpler answer: Split the ML pipeline into its own repository.
But wait, access control alone doesn’t justify the split.
Monorepos have permission tools. The real reason is coupling.
Look at how the ML pipeline actually works:
-
Receives videos through a queue
-
Processes asynchronously
-
Writes results to database
-
Mobile app doesn’t know it exists
-
You never touch the ML code
-
Backend dev rarely touches it
This is loose coupling at the domain level.
The ML pipeline is a separate bounded context. Its concerns (model training, inference, video processing) are distinct from core product concerns (user management, workouts, coach analytics).
The queue is the natural boundary.
Access control is the catalyst. Loose coupling makes the split sustainable.
You restructure to:
fitnessfiction-backend/ (You + Backend dev)
├── api/ (Backend dev focuses here)
└── coach-dashboard/ (You focus here)
fitnessfiction-mobile/ (Mobile dev)
└── app/ (React Native)
fitnessfiction-ml/ (ML contractor)
└── pipeline/ (Python - video analysis)Each repository now has clear ownership and appropriate access controls.
You and the backend dev continue working in the backend monorepo - you on coach dashboard and business rules, the backend dev on API infrastructure and performance.
The mobile dev works independently on mobile with their own release schedule.
The ML contractor has access only to the pipeline code, with clear interfaces for receiving videos and writing results.
Communication between these repositories happens through well-defined contracts. Backend to mobile uses OpenAPI-generated clients. Backend to ML uses a message queue with a documented schema. Each service can evolve independently as long as it respects the contract.
This is how hybrid approaches emerge in practice. Not from some grand architectural plan, but because different constraints (team ownership, deployment cadence, security requirements) force different parts of your system to split at different times. You adapt the structure to reality, not the other way around.
The Simple Rule
When someone asks “Mono or poly?”, apply this:
Count the teams owning tightly coupled services.
One team → Monorepo (coordination happens naturally)
Multiple teams, coordinated roadmaps, working in locksteps → Monorepo (accept overhead)
Multiple teams, autonomous → Polyrepo (use contracts)
For FitnessFiction, the structure evolved:
Started with everything in monorepo as solo engineer. Split mobile when specialists were hired with different deployment cycles. Separated ML when security and access requirements demanded it.
The lesson: Repository structure adapts to actual constraints, not theoretical ones.
When team ownership changes, when deployment realities shift, when access control becomes critical—that’s when you reorganize. Not before.
How to Think This Through
When you’re facing this decision on your next project, use this mental model:
Start with coupling
Look at your last twenty pull requests. Or estimate based on planned features. Count how many touch multiple services.
If more than sixty percent do, your services are coupled. That’s your baseline signal.
Factor in team structure
Count teams, not people. Teams have:
-
Separate priorities
-
Separate roadmaps
-
Different sprint planning
If the same people work on coupled services → monorepo reduces friction.
If separate teams own coupled services → you’re trading repository complexity for coordination complexity.
Check deployment realities
Do services deploy on the same schedule?
Different release cycles (App Store vs web) create friction monorepo can’t solve. Deployment physics matter more than repository philosophy.
Consider access requirements
Security, compliance, or contractor access might force separation even when coupling suggests staying together.
Sometimes organizational constraints override technical ones.
Default to simple
Start with monorepo for small teams (fewer than five people). Split when team structure or deployment reality forces it.
On migration: Moving from monorepo to polyrepo is usually easier than the reverse. But neither is trivial. You’ll face:
-
Extracting shared libraries
-
Untangling implicit coupling
-
Rewriting CI pipelines
The point isn’t that migration is easy. It’s that starting simple defers complexity until you have real information about what you need.
The tooling caveat: Monorepos beyond a certain number of people need serious build tooling. Without tools like Nx, Turborepo, or Bazel running only affected tests, CI times explode. Google’s monorepo works because they built Bazel with dedicated teams.
If you can’t invest in tooling, split repos before the pain becomes unbearable.
The Real Lesson
This decision isn’t about technology. It’s about people and workflow.
Repository structure should match team structure.
When one team works on tightly coupled features → monorepo reduces friction.
When multiple autonomous teams work on loosely coupled services → polyrepo enables independence.
The common mistake:
Optimizing for hypothetical future scale. Copying what big tech does. Google’s monorepo works for Google because they have thirty thousand engineers and dedicated tooling teams. That’s not your context.
The better approach:
Optimize for how your team works today.
One team shipping coordinated features? Monorepo.
Multiple teams with different priorities and deployment cycles? Polyrepo.
Remember: This decision isn’t permanent.
As your team grows and evolves, your repository structure should evolve too. FitnessFiction showed this clearly:
-
Solo founding engineer → monorepo
-
Hire specialists → split mobile
-
Bring on contractor → split ML
Repository structure follows team structure. When team structure changes, repository structure should change too.
Start simple. Split when needed. Don’t overthink it.
The best repository structure helps your team ship features faster with less coordination overhead. Everything else is just implementation details.
Want to go deeper?
This framework implicitly applies Conway’s Law and Team Cognitive Load principles.
Look into Team Topologies, bounded contexts, and deployment units if you want the formal theory behind these ideas.